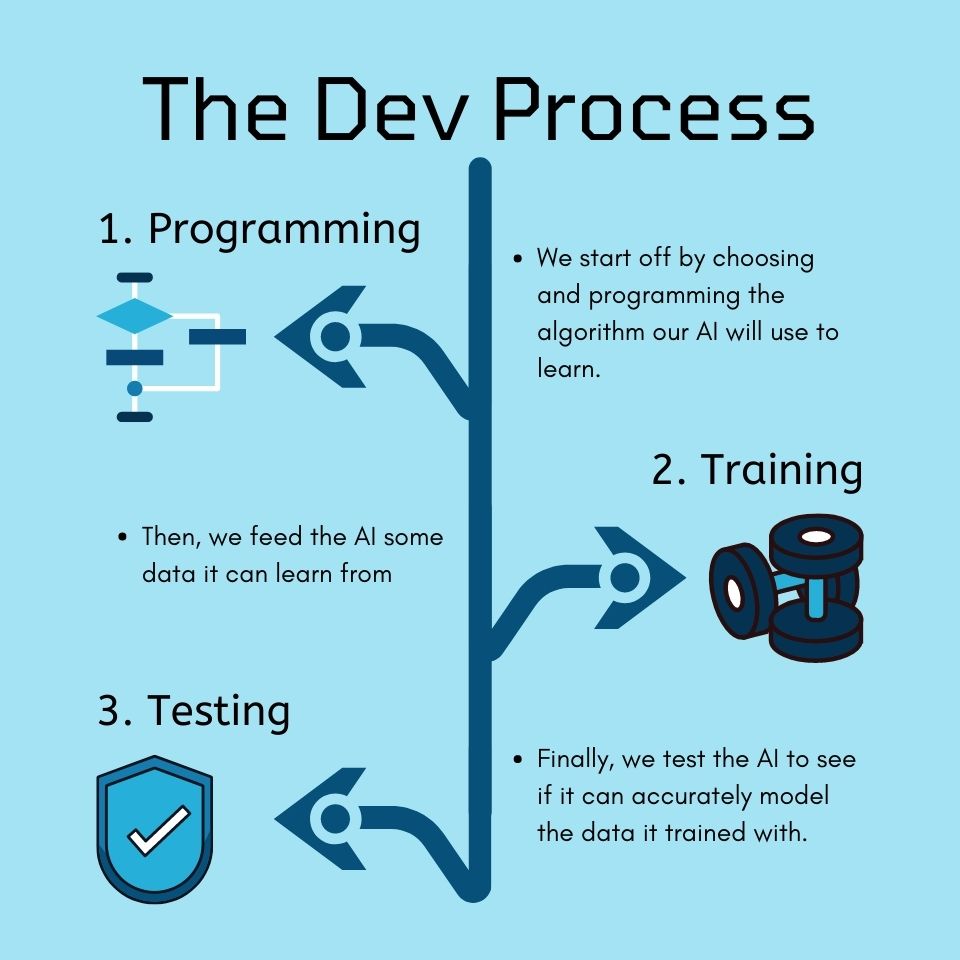
When we develop Artificial Intelligence, we first have to decide how it will
become intelligent in the first place. Remember that we defined
intelligence as the ability of something to reason, learn, solve, perceive, and
communicate. Of all these components, learning is the most difficult to
implement. As we have said before, humans learn in many different ways, such as
observation, trial and error, and pattern recognition. That last bit serves as
the basis for machine learning, which, as the name implies, is a method of
making machines learn. It helps computers learn on their own.
After that, we then determine the dataset the AI will use to train itself.
The dataset must be carefully selected because, as we have discussed
previously, an AI will acquire any bias in the dataset used for training.
Finally, we have to test the AI one way or another. The testing method
will heavily depend on the machine learning algorithm used to train the AI.
Supervision
A machine learning algorithm is a method of implementing machine learning.
There are two general types of machine learning algorithms. One of them is
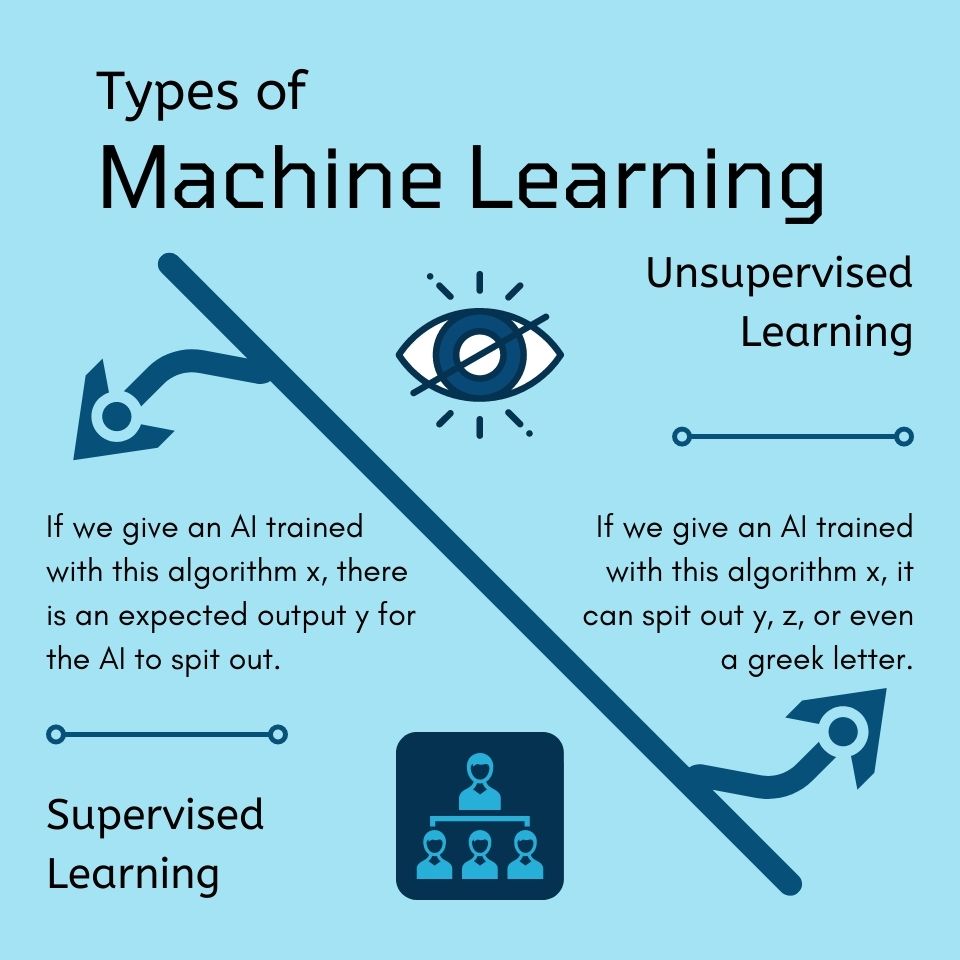
known as supervised algorithms. Simply put, supervised algorithms have a
"correct answer" on paper. Say, if we give an AI trained with a supervised
algorithm a number x, there is an expected value y for the AI to spit out. AIs
trained using this algorithm are best suited to solve classification and
regression (i.e., estimating the relationship between two things) problems.
The other general type of machine learning algorithm is known as unsupervised
algorithms. In simple terms, unsupervised algorithms do not have a "correct
answer" on paper. If we give an AI trained with this type of algorithm x,
it can spit out y, z, or even a greek letter. AIs trained using this algorithm
are best suited to solve clustering (i.e., spotting groups in a pool of data)
and association (i.e., finding connections between two things) problems.
Hand-picking Data
After creating our machine learning algorithm, we must find and prepare the
AI's training dataset. Again, remember that an AI will acquire any bias in
the dataset used for training. Therefore, choose your data wisely and make sure
that:
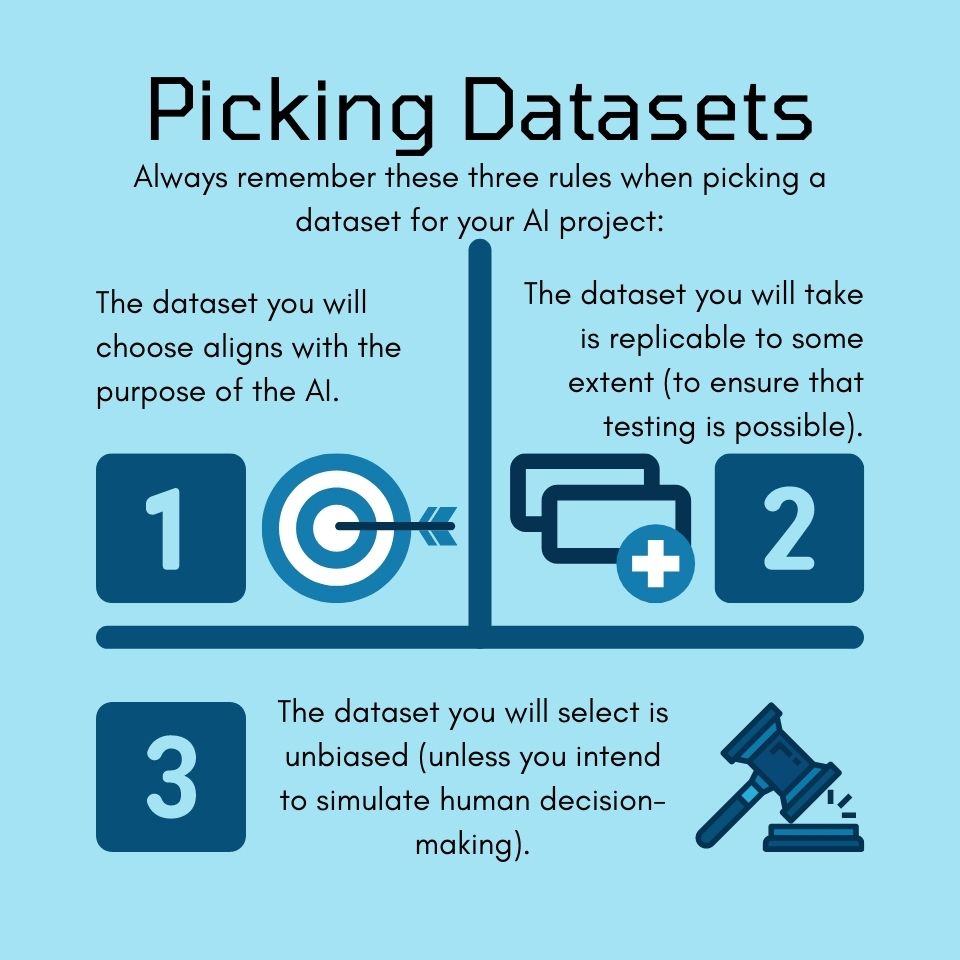
The dataset you will choose aligns with the purpose of the AI.
The dataset you will take is replicable to some extent (to ensure
that testing is possible).
The dataset you will select is unbiased (unless you intend to
simulate human decision-making).
Preprocessing
After finding a dataset to work with, you must process the data before use
(i.e., preprocess the data). The way you will process the data will depend
on its function in training the AI. Let's say your AI only needs to look into
the data as percentages of the range (i.e., the difference between the maximum
and minimum values). In other words, 0% is the lowest value, 100% is the
highest value, and 50% is halfway between the two. Here, you must perform a
preprocessing technique known as min-max scaling, which expresses all the
values in the dataset as a percentage of the range.
We also have to remember that, at this stage, our AI can only understand
numerical data; it cannot comprehend words yet. Therefore, if we want the
AI to analyze quantitative (descriptive) data, we must somehow convert the
descriptions to numbers before passing it to the AI. This process is known as
label encoding. Most of the time, this process occurs in two steps:
alphabetization of descriptions (or labels), followed by assignment of numbers
to each item.
Testing and Deployment
Once we have trained our AI, we then have to test it. Again, the testing
methods we will use depend on the machine learning algorithm used by the AI:
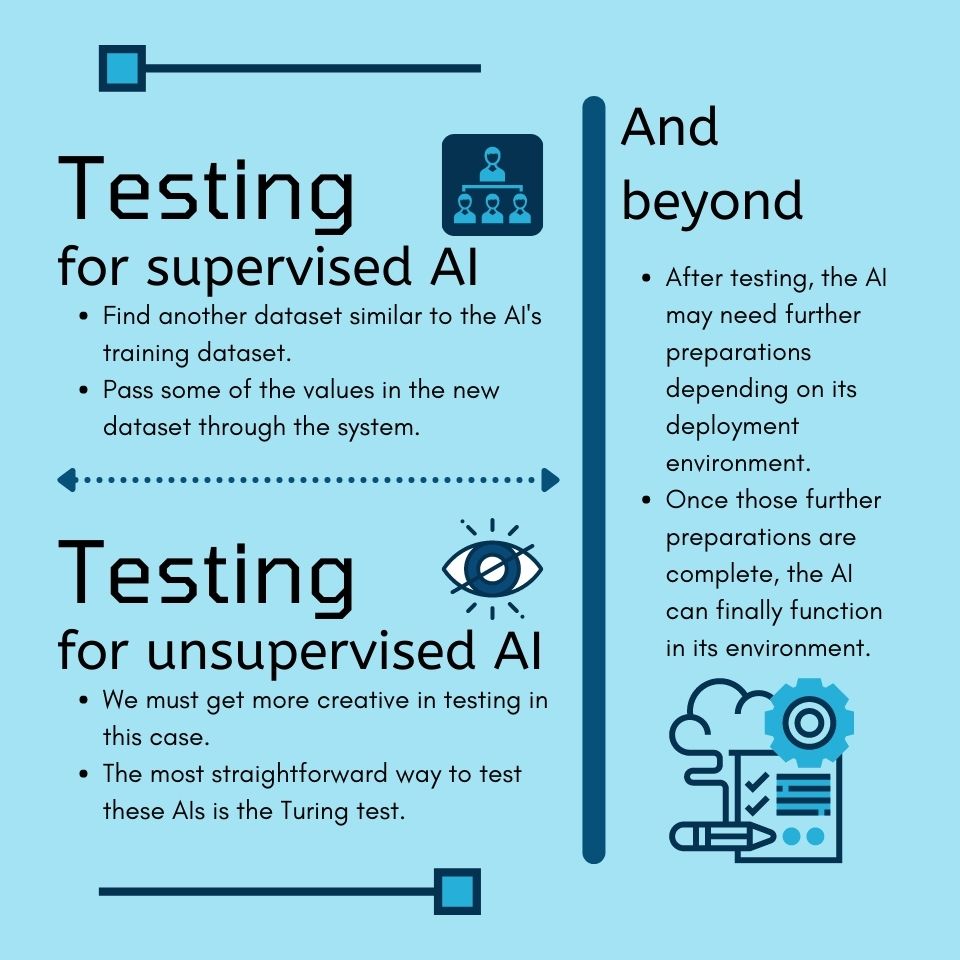
For AIs based on supervised algorithms, we must first find another
dataset similar to the AI's training dataset. Then, we shall pass
some of the values in the new dataset through the system and see if
the results make sense.
Meanwhile, for AIs based on unsupervised algorithms, we must get
more creative in testing them as they do not have an expected
output. The most straightforward way to test these AIs is the
Turing test.
After testing, the AI may need further preparations depending on its
deployment environment. For example, an AI built into a robot must learn to
control the robot's parts first before deployment. AIs inside artificial
environments must learn to navigate the artificial environment first (i.e.,
know where all the input and output fields are) before roll-out. Once those
further preparations are complete, the AI can finally function in its
environment.
Now It's Your Turn!
In truth, making a simple AI is much easier than it seems!
You can use Python as your programming language of choice for making
AIs. It is easy and quick to learn due to its simple syntax. Python is
also easy to read, easy to maintain, highly capable (has many
functions), portable (can run on many different systems), extendable
(allows access to low-level components), and scalable (allows small
projects to grow without much difficulty).
There is a whole repository of python projects that can help you in
your journey to making an AI. Just go to
this website and start browsing!
There are countless tutorials on Youtube that teach you how to create
an AI with Python and programming with Python in general. All it takes
is a simple search, and you should be able to take off from there!